Execution Engine Overview
Overview
Data Analysis / Engineering requires computation resources to execute the task. In Ananas Analytics Desktop, we call it Execution Engine. You build your analysis board on your own computer. Once it is tested, you need to decide where to run your analysis jobs to get the final results.
Empowered by Apach Beam, Ananas embraces the industry standard data analysis engines, such as Apache Spark, Apache Flink, Google Dataflow, and more.
Ananas Analytics Desktop embeds a local Flink execution engine, which makes it possible to run your analysis job on your own computer directly. The local Flink execution engine is very powerful, we have been using it analyzing Gigabytes data, which is not possible to analyze with traditional desktop analysis tools like Excel.
However, in big data era, the great chances are, your data volume is an order of magnitude larger than Gigabytes (Terabytes), or your computer's commputation power is not large enough. Which means you 'll wait hours to get the result.
Ananas Desktop comes to the rescue. It is now possible to run your analysis job on a data engine cluster. It could be a on premise infrastructure prepared by your devops team, or a SaaS cloud offering like Google Cloud.
When running analysis jobs on Cloud or On premise infrastructure, you need to make sure your data sources and destinations are accessible from it. The common mistake is trying to process a local file on a cloud execution engine, instead, you should upload the file to a cloud storage which can be accessed by the execution engine infrastructure and use corresponding source step to access it.
Currently, Ananas Desktop supports 3 types of execution engine:
More engines coming soon ...
Add an execution engine
By default, Ananas executes the analysis job with the embedded Flink engine. To run analysis job on a different engine, click the Execution Engine tab on the left sidebar. And click + to create a new execution engine profile.
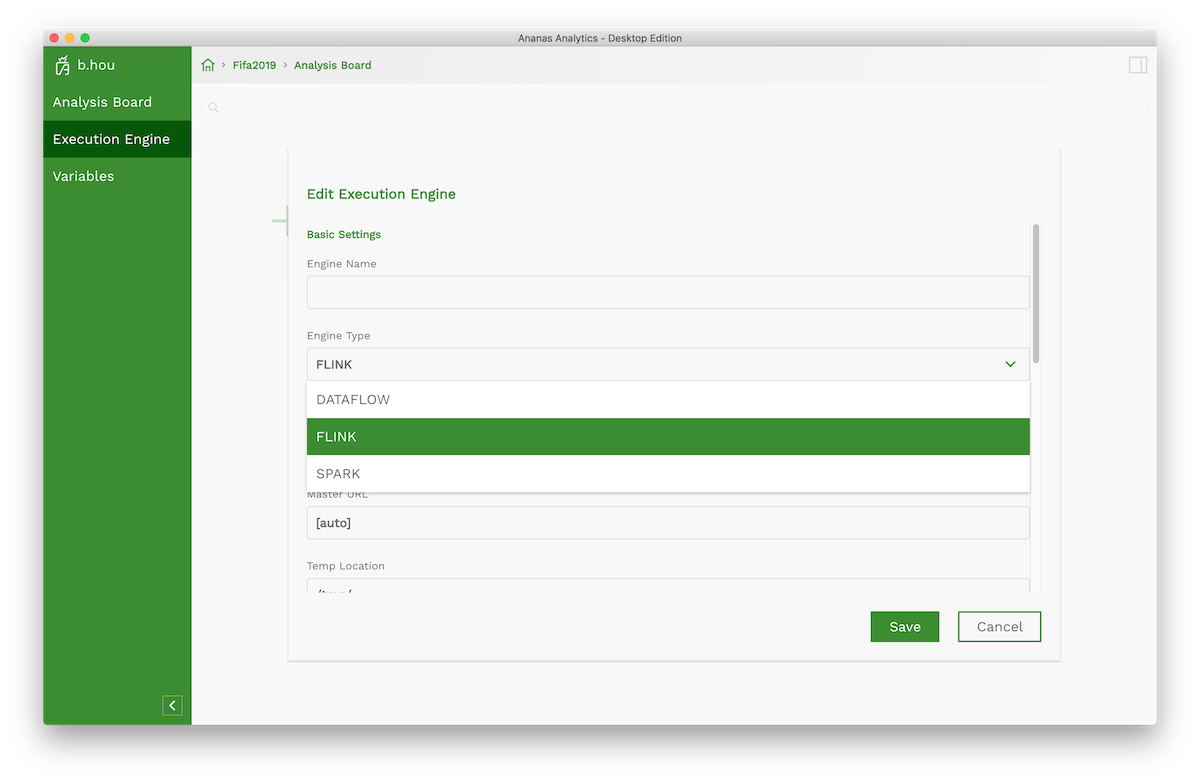
In the Execution Engine Edit page, choose the execution engine type, and fill the other configurations according to the type. You can get a more detailed guide of each engine from the Execution Engines user guide category
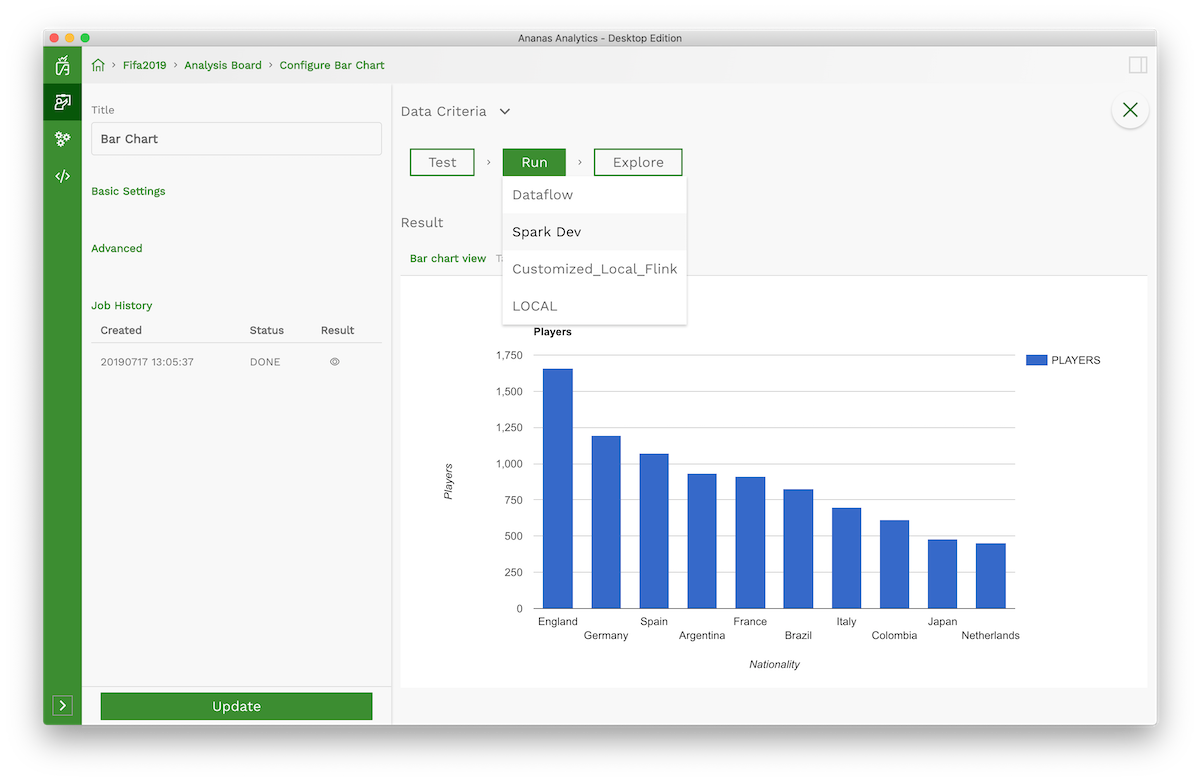
Run analysis job with your engine
Once you create your first execution engine. Open any destination or visualization step. Click RUN button, you will get a drop-down list to choose any execution engine, on which you want to run your analysis job.
Note: You can only run destination and visualization steps.
Tips
You can use variables in Execution Engine settings too.